Building Flaneur: A Creation Log

TL; DR
Our team participated in the Hack Engine event hosted by Jike from April 8 to April 10. This post documents the birth of our project Flaneur — a website that uses AI to generate music, ambient sound, and narration, designed to feel like walking with an old friend. I also discuss other projects showcased at the event, including travel planning and knowledge management.
What Is Hack Engine
Here’s the official introduction to Hack Engine:
Q: What’s the difference between Hack Engine and a Hackathon? A: None. Except we’re also an incubator, a fund, and an alumni founder network. Q: So it’s basically Y Combinator? A: Yes.
In short, Hack Engine organized an AI-themed hackathon. Each team of up to five people had 48 hours to build and demo a small product.
Our team had been closely following the development and applications of generative AI, and since I was a longtime Jike user, the decision to join was easy. We were curious to see what people would build with AI, and wanted to meet the real faces behind familiar usernames.

Our team of five: backend engineer @Xiao, frontend engineer @Edison, designer @Brant, generalist @Jason (me), and algorithm engineer @York, who we recruited from a ski group (?). None of us had much hackathon experience, so before heading out we consulted @Junyu. His former company Wandoujia was likely the first in China to hold internal hackathons — typically 24-hour sprints to build a small app. When I asked about his most memorable experience, @Junyu looked up at the sky (cloud computing?), then recalled a year when the hackathon coincided with a massive rainstorm in Beijing. Everyone pulled an all-nighter anyway, debating midway whether they should go outside to rescue people. @Junyu gave me three pieces of wisdom: the most important thing is to finish building, the second is to make it interesting, and the third… there was no third.
Since the theme wouldn’t be announced until kickoff day, we didn’t over-prepare. On the engineering side, we set up a server capable of running Stable Diffusion and prepared OpenAI API keys on two different accounts in case one got suspended. Combining @Junyu’s advice with our instincts, we established a few principles for topic selection:
- Fun and interesting, sufficiently small and vertical
- Achievable in two days
- Or not achievable in two days but impressive enough to fake it (just show a video as the demo? (fake it till you make it
Copilot for ?
Saturday morning, 9:30 AM. The theme was announced: Copilot for X.
Copilot for X, where X = anything — so essentially nothing was said at all! To avoid premature convergence, we decided to brainstorm individually first, then regroup. I had planned to use the time to socialize, but was startled to find other teams already deep in heated discussions or already building. By the time we reconvened, we were hungry. Food first.

The event was in Wujiaochang, an area none of us knew well. Not knowing where to eat, we just started walking and talking. And that’s when the idea came.
Shanghai is a city made for walking. I remembered a time years ago, walking alone on Hengshan Road on a summer evening, the night breeze blowing, music in my ears. The song was “Tram” by Shu Qi, from the Hong Kong edition of Louis Vuitton’s SoundWalk series (yes, Hong Kong). LV selected iconic locations in the city, commissioned local musicians to compose pieces, and had Shu Qi narrate stories woven into the soundscape. It was beautiful. But the series only had three Chinese-city editions — Beijing, Shanghai, and Hong Kong — and I’d listened through them quickly. Beijing was narrated by Gong Li, Shanghai by Joan Chen. I highly recommend actually walking the routes from the albums while listening.
Of all the tracks in the series, “Tram” remained my favorite — Shu Qi’s voice is simply extraordinary. So I thought: what if AI could generate similar content, layered with AI-generated background music? That could be something.
We discussed it and agreed it was feasible, and the idea expanded: we could incorporate real-time information like current weather, the user’s movement state, walking pace — so that even at the same location, the experience would be different each time. We could also pull in data about nearby landmarks and buildings.
We mapped out the requirements. The product would have these characteristics:
- Zero interaction required — just open it and go
- Generates background music matched to walking pace, based on current location, weather, and movement
- A pleasant female voice narrates the history and stories of nearby streets, as if a real person were walking beside you
- Pre-generates content for the current and adjacent blocks, so the narration never stops as you walk

The end result would be a stripped-down LV SoundWalk. Or think of it this way: LV SoundWalk is impossibly elite, covering only a handful of locations. But every inch of the ground we walk on has its own stories. Every place deserves its own SoundWalk. You could call it the democratization of SoundWalk.
Saturday, 2 PM — concept and division of labor complete. Time to build.
The Birth of Flaneur
@Junyu: The first step of building a product — buy a domain name.
First, we needed a name.
Shanghai is a city of extraordinary sophistication. The day I first arrived, I took the subway from the airport to the city center. Stepping out of the station, I saw a young woman dressed with impeccable care, holding a bouquet of flowers wrapped in an English-language newspaper. How cosmopolitan, I thought. Then I looked closer and realized I was wrong — it wasn’t English. It was French. Shanghai really is something else, I thought again.
Since it was walking in Shanghai that gave us the idea, and Shanghai was where we were building it, the name had to have some panache.
So we named it Flaneur — French for “to wander,” specifically “to wander with no particular purpose.” Given that Flaneur requires absolutely no user interaction, the name was fitting beyond measure.
The implementation of Flaneur can be roughly summarized in these steps:
- Retrieve the user’s contextual information: geolocation, movement state
- Fetch data associated with that location: current weather, Wikipedia entries, POIs
- Use GPT to generate a narration incorporating the information from step 2
- Convert the narration from step 3 into natural-sounding speech via TTS (Shu Qi’s voice)
- Based on location, weather, and movement state from steps 1 and 2, generate appropriate background music — mellow for walking, upbeat for running
- Merge the audio tracks from steps 4 and 5 for playback
- For demo purposes, we still needed a UI to display scrolling text from step 3
There wasn’t much engineering difficulty. The only issue was that browsers can’t access the user’s movement state, so we dropped that feature. The interesting part was the AI implementation, which broke down into three areas: text generation, text-to-speech (TTS), and music generation.
The voiceover narrations in LV SoundWalk are richly atmospheric, weaving together local history and character. Getting GPT to generate text in a similar style was crucial, and that task fell mostly to me. Using Wujiaochang as an example, I fed GPT some Wikipedia material as prompts and asked it to play the role of a “walking companion” introducing the area. But the output kept reading like a tour guide script. I tried adding more “in-the-moment” descriptions, like “you just passed an old wooden door,” which helped somewhat. Yet GPT couldn’t resist opening with “Welcome to Wujiaochang” or “Hello, old friend.” What I wanted was a gentle female voice that simply appears in your ears — no pleasantries, no small talk, just direct conversation (otherwise it would feel awkward, especially from a voice that beautiful).
Then it hit me: I had GPT play the role of “describing a nearby neighborhood to a blind friend.” The results were remarkably good! Though GPT kept adding consoling lines at the end like “Even though you can’t see, you can still feel…” Following the same logic, I refined the prompt. Here’s what the final prompt and output looked like:
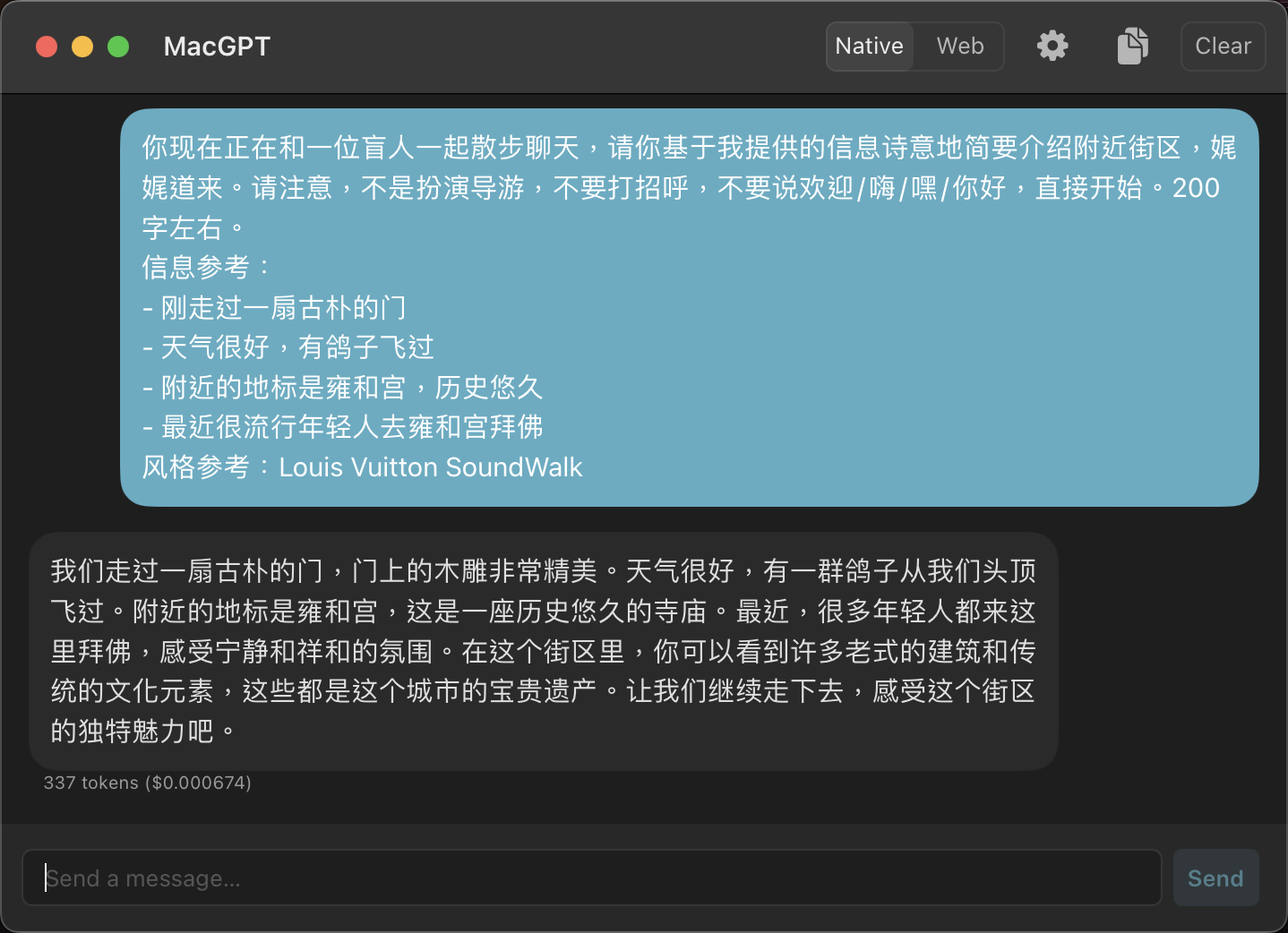
TTS was the most challenging part of the entire process. Text-to-speech has many mature solutions — you’ve heard those ubiquitous voices on Douyin saying things like “Family, who understands” and “Pay attention, this man’s name is Xiaomei.” But Flaneur clearly couldn’t use voices that generic. If not Shu Qi, at least Gao Yuanyuan. So we researched custom TTS options and found two viable approaches:
- MockingBird: An open-source model that can generate speech from just a few seconds of source audio. Requires self-hosting. Demo quality was acceptable.
- 11Labs: Upload a 10-minute audio sample and it can generate speech for any text. The results were stunning. Paid service (seemingly affordable). Downside: English only.
Some domestic Chinese vendors offered custom voice solutions, but they required 15+ business days and costs in the hundreds of thousands of yuan. They appeared to be using legacy technology, which explained the high costs.
@York invested enormous effort deploying and optimizing the MockingBird model, but the results remained underwhelming. We studied the underlying technology and found that MockingBird was built on the previous generation of GANs — likely the reason for its mediocre output.
While @York was grinding away at the model, I started playing with 11Labs. I first tried Shu Qi’s voice reading Chinese — the result sounded like a foreigner who’d just taken the HSK exam. Shu Qi’s voice reading English lacked a certain magic. What about a well-known Western actress? My first thought was Scarlett Johansson and the film Her.
The result was extraordinary. We couldn’t “have” Shu Qi, but we accidentally got Samantha. What more could you ask for?

Who could have seen this coming!
Music generation was the most straightforward part. Software that generates BGM matching your walking BPM has existed for years — not much imagination required. Given our time constraints, I decided not to invest too much effort in background music. We’d just pre-generate a batch of tracks with different tempos using AI and play them during the demo.
Since the interface was simple, we finished the UI development and API integration on day one. The most time-consuming parts were the backend work by @Xiao and the TTS by @York. We got all the APIs working by the evening of day two. Both days we left the venue right at midnight — many teams were still grinding away.

Time to slip away.
So, How Did It Turn Out?
Here’s our demo video: YouTube
A quick walkthrough:
- Opens and works instantly, no interaction needed
- All content is AI-generated — the narration, the music, and Samantha’s captivating voice (the music was pre-generated, but still AI-made)
- We even embedded an ad as an easter egg (who knows, maybe there’s a business model here)
Try it yourself: https://flaneur.polytimeapp.com/ Please open on mobile.
After opening, tap the bubble in the center to start playback. Loading is still a bit slow, and the generated content can be somewhat monotonous — please be patient with Flaneur.
When we first conceived the idea, LV SoundWalk was our sole inspiration. But when I actually used Flaneur and heard Samantha’s voice narrating, I wanted to talk back to her.
I love walking. Sometimes to think, sometimes with friends. The most comfortable state is wandering through an unfamiliar neighborhood with a close friend. I tend to have strange associations and deadpan observations, and unfamiliar surroundings give me more material. Walking, riffing, and having someone actually respond — that’s the ideal state.
Take it a step further: if we could access the phone’s camera, use a CLIP model to understand what it sees, and feed that as part of the prompt to GPT — then Samantha, or rather Flaneur, could actually see what you see. She would truly be like an old friend walking beside you, listening to your ramblings, accompanying you street after street. Just like in the film Her. And Her came out a full decade ago. Its filming locations happened to be in Shanghai.
There’s a sense of a dream becoming reality. Wow.

Demo Day!
Demo Day meant a hundred teams presenting their work in a single day. Thrilling! Each team had only 5 minutes — go over time and you’d be ruthlessly cut off. Brutal! I couldn’t wait to see everyone’s projects. Let’s go!
We were scheduled fourth from last. By then I was honestly struggling to stay awake. But the presentation went smoothly. We said everything we wanted to say, so there isn’t much to add.
I listened carefully to almost every project and took notes on the ones I found compelling, interesting, or impressive. @Junyu was more diligent — he recorded notes on every single one. Since the organizers likely have some confidentiality concerns, I’ll stick to abstract impressions.
Several projects combined AI with social good, which I really appreciated. The generative AI wave has many people worrying about being replaced (especially lawyers, programmers, and investment researchers). I happened to be discussing the history of technological revolutions with a friend just yesterday. Every major shift has ultimately been a liberation of human potential. In the short term, some jobs may be displaced, but what quickly becomes clear is that people are being freed from “work that isn’t very human” to do “work that’s more essentially human.” AI can churn out content-farm clickbait, but it can also help visually impaired people interact with the world more seamlessly.
Quite a few projects focused on travel planning. We had considered this theme too, but realized the fundamental problem: we had no data. Dynamic flight pricing, hotel room rates, even map routing — these are all constraints, and all that data is locked behind OTA platforms with aggressive anti-scraping measures. You could build a beautiful product with nothing to feed it. Since the mobile internet era, data has been held tightly by major corporations, trapped in app silos. Users have internalized habits — “rides mean Didi,” “videos mean Douyin,” “feeling reckless means Baidu” — yet all of these are fundamentally just information, not “video / text / voice / maps” or “notes / email / calendar / to-do.” It’s hard to argue this hasn’t been a detour in the history of the internet.
The most popular theme at Hack Engine, and the one that interested me most, was what I’d call “generalized knowledge management.” GPT is a language model — it doesn’t possess logical reasoning capabilities. Human knowledge exists within logical relationships. The proposition “the Earth is round” isn’t what matters; what matters is “gravity causes Earth’s matter to accumulate toward its center, therefore the Earth forms an approximate sphere.” Epistemology defines knowledge as Justified True Belief (JTB) — a belief must simultaneously satisfy three conditions:
- A person believes something;
- The belief is actually true;
- The belief is justified.
All three are necessary. Some counterexamples: “Gravity causes Earth’s matter to accumulate toward its center, therefore the Earth became a bagel” (the belief is factually false). “There’s a hamster running on a wheel inside the Earth, which is why it’s round” (the justification is wrong).
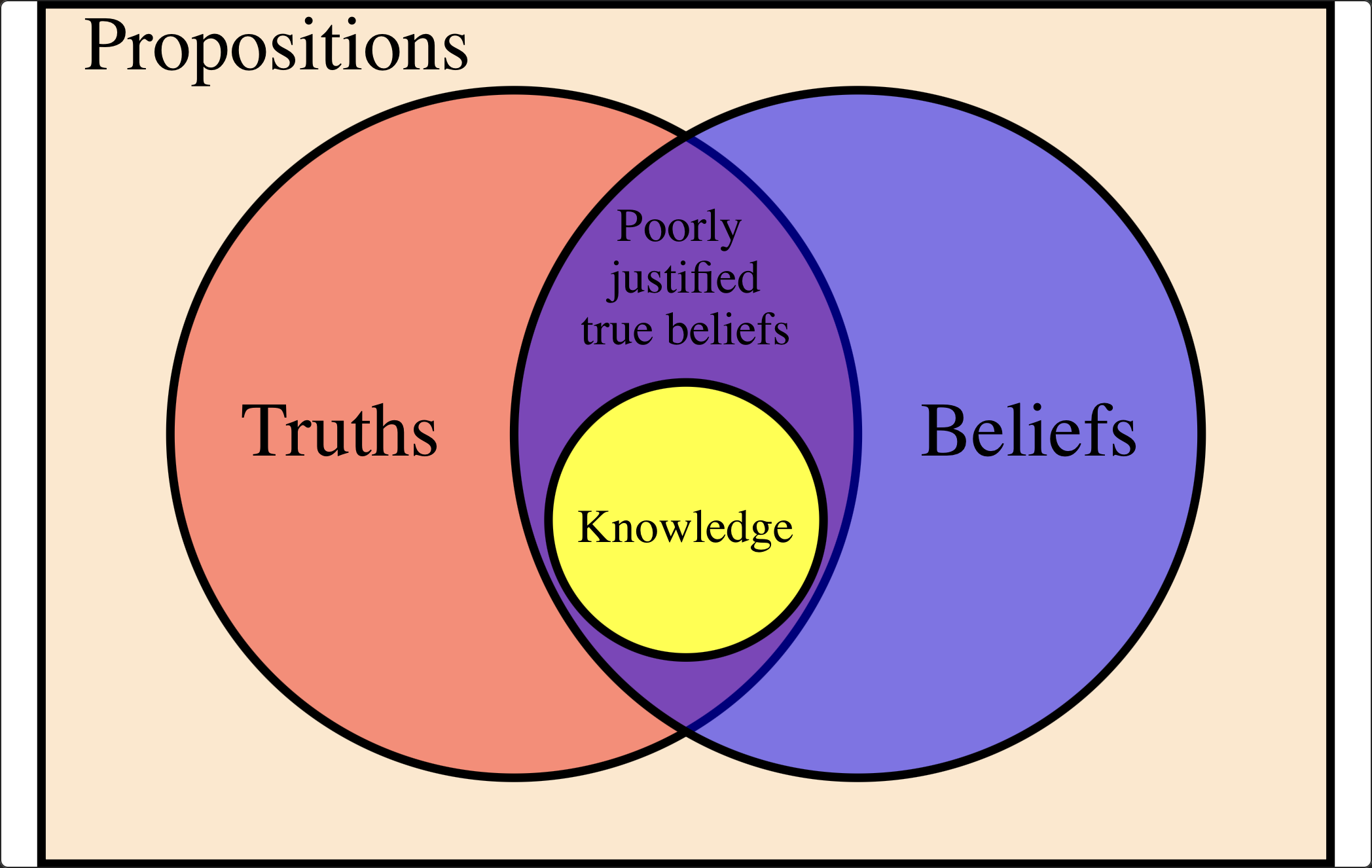
GPT stands for Generative Pre-Trained Transformer. It’s fundamentally a “large language model.” The launch of ChatGPT felt more like a tactical move to capture user attention and data — not necessarily evidence that GPT’s ideal form is conversational. Yet everyone is building chatbots now. I think OpenAI led us into a rut. Moreover, as I argued, GPT lacks logical reasoning, so asking it knowledge-based questions is unwise. Everyone has seen GPT confidently fabricating nonsense (hence its nickname “Bullshit Generator”).
On the other hand, I believe GPT excels at content processing and generation within bounded information — for instance, in Flaneur, all raw information was provided by us. Other applications: pre-filtering a “read it later” list; generating article summaries (the TL;DR at the beginning of this post was written by GPT); automatically establishing connections within a knowledge base (which really only requires embeddings); generating a new article from fragmented notes…
I call this “generalized knowledge management.” It’s a subject I’m deeply passionate about. If you share this interest, I’d love to exchange ideas.

Building the collective human intelligence.
Ending
Hack Engine ran at a brisk pace. Demos finished on time, even ahead of schedule, and results were announced that same Monday evening. Flaneur didn’t make the cut. There was some disappointment. But we genuinely enjoyed the process and had an unforgettable weekend. The weather in Shanghai those days was lovely too — the forecast had called for rain, but *** arrived and the skies cleared.
Shanghai always seems to give me the same feeling: a beautiful beginning and journey, with a hint of regret at the end.
Anyway, huge thanks to my team, and special thanks to @York for traveling from Hangzhou to join us (we somehow forgot to take a group photo TAT).

I want to especially thank the Jike team for organizing. We had a near-perfect on-site experience, encountering zero issues — remarkable for what was apparently their first event of this kind. Hack Engine paid attention to the small things, too — the participant badges were custom-designed. The details, chef’s kiss.
 Classier than a ByteDance employee badge. May Jike acquire ByteDance someday.
Classier than a ByteDance employee badge. May Jike acquire ByteDance someday.
Although Flaneur didn’t win, it was widely liked. Many people asked if we would continue developing it, which made us very happy. Honestly, we haven’t decided. Building a demo and building a real product are very different things. Whether current technology can deliver the experience we envision still needs investigation. And our team faces real constraints — carving out the time and resources for another product won’t be easy.
Anyway, if you like Flaneur, please don’t hesitate to let us know!
2023-04-13 @Shanghai